声明
本教程为原创教程,转载请注明出处http://kongtianyi.cn/2016/09/28/python/Scrapy-Lesson-3/
本节内容
本部分所实现的功能是,批量的爬取网页信息,不再是像以前那样只能下载一个页面了。也就是说,分析出网页的url规律后,用特定的算法去迭代,达到把整个网站的有效信息都拿下的目的。
因为本部分讲完后,功能已经到了可以使用的地步,所以我把本部分的结果独立出来,把项目上传到了github,小伙伴可以下载参考,地址https://github.com/kongtianyi/heartsong。教程余下的其他部分是添加功能和优化,今后我会另外创建一个ex项目上传到github。
分析url
不管是Discuz模板,phpWind模板,还是百度贴吧,甚至某些新闻网,都是采用id的方式来组织网页url的。这就给我们编写定向爬虫带来了极大的便利。好,来看一下Discuz模板心韵论坛的url:1
2
3http://www.heartsong.top/forum.php?mod=viewthread&tid=13&extra=page%3D1
http://www.heartsong.top/forum.php?mod=viewthread&tid=31
http://www.heartsong.top/forum.php?mod=viewthread&tid=31&extra=&page=2
共同点一目了然,其实我们不妨把参数改一改,空的参数去掉,下面三个url跟上面的三个请求到的页面是一样的1
2
3http://www.heartsong.top/forum.php?mod=viewthread&tid=13
http://www.heartsong.top/forum.php?mod=viewthread&tid=31
http://www.heartsong.top/forum.php?mod=viewthread&tid=31&page=2
局势更清晰了,所谓的tid,就是帖子的id,而参数page,就是若主题帖分页的话,主题帖的某一页,当然第一页也可以加上page参数,http://www.heartsong.top/forum.php?mod=viewthread&tid=13&page=1,一样可以请求到网页。
大部分的网站首页上都会有“最新帖子”,“最新新闻”这种模块,点进去就能找到tid的上限,若是没有的话,那就乖乖多次尝试吧,下限一般都是从零开始,不必多说。而page参数,需要我们在主题帖的第一页通过网页元素的分析去寻找出来。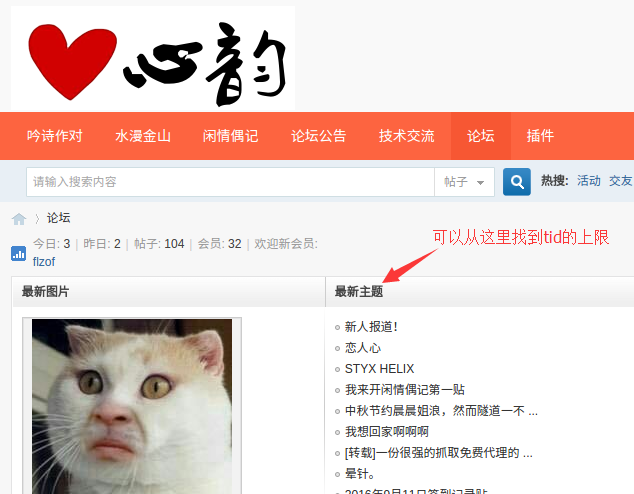
根据我的经验,在很多论坛里,包括我的这个小破论坛,都或多或少的遭到广告的侵袭,会有很多tid对应的帖子被管理员删掉,所以下面的代码里我们要对这种帖子做相应的处理。一般来说,Discuz被删帖的tid或者是还没排到的tid会返回如下页面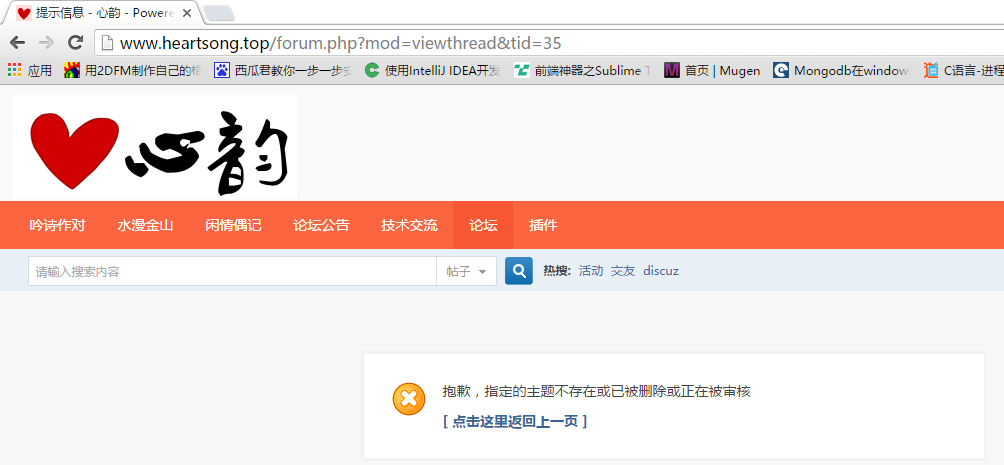
爬取思路
通过以上的分析,我们可以得出这样的思路:
1 通过某种机制去迭代tid
2 在主题帖第一页中分析出总页数,去迭代带page参数的url
一些杂项
对于某些网站,他们有识别爬虫的机制,所以我们需要对我们的爬虫进行一定的伪装,在heartsong_spider.py中加入以下项。
其中,cookies在后面教程的回帖部分会用到,此处可以先置空。1
2
3
4
5
6
7
8
9
10
11
12
13
14# 用来保持登录状态,可把chrome上拷贝下来的字符串形式cookie转化成字典形式,粘贴到此处
cookies = {}
# 发送给服务器的http头信息,有的网站需要伪装出浏览器头进行爬取,有的则不需要
headers = {
# 'Connection': 'keep - alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
# 对请求的返回进行处理的配置
meta = {
'dont_redirect': True, # 禁止网页重定向
'handle_httpstatus_list': [301, 302] # 对哪些异常返回进行处理
}
重载start_requests
在找到tid的上限后,要想带着上面配置的杂项去发起Request请求,我们需要重载一个函数,配置使用star_urls所发起的第一条请求。
这里对heartsong_spider.py中的yield做一下解释,它既可以传出一个item到pipeline进行加工,也可以传出一个新的Request请求。在传出一个新请求的时候,就会多开启一个线程,Scrapy是异步多线程的爬虫框架,不需要我们对多线程有过多的了解。1
2
3
4
5
6
7
8
9def start_requests(self):
"""
这是一个重载函数,它的作用是发出第一个Request请求
:return:
"""
# 带着headers、cookies去请求self.start_urls[0],返回的response会被送到
# 回调函数parse中
yield Request(self.start_urls[0],callback=self.parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
编写迭代tid的函数
找到了tid的上限之后,我们的策略是从上限向0迭代,当然,要生成新的url,只需要对老的url串进行简单的处理就OK了1
2
3
4
5
6
7
8
9
10
11
12
13
14def get_next_url(self, oldUrl):
'''
description: 返回下次迭代的url
:param oldUrl: 上一个爬去过的url
:return: 下次要爬取的url
'''
# 传入的url格式:http://www.heartsong.top/forum.php?mod=viewthread&tid=34
l = oldUrl.split('=') #用等号分割字符串
oldID = int(l[2])
newID = oldID - 1
if newID == 0: # 如果tid迭代到0了,说明网站爬完,爬虫可以结束了
return
newUrl = l[0] + "=" + l[1] + "=" + str(newID) #构造出新的url
return str(newUrl) # 返回新的url
迭代request请求
有了找到下一个url的函数之后,我们就可以在适当的位置添加如下代码,发起新的请求,“适当的位置”包括以下两种情况:
- 本页的数据获取完成
- 本页被删除,无内容
1 | # 发起下一个主题贴的请求 |
分析总页数
打开一个有分页的主题帖,和一个没有分页的主题贴,找不同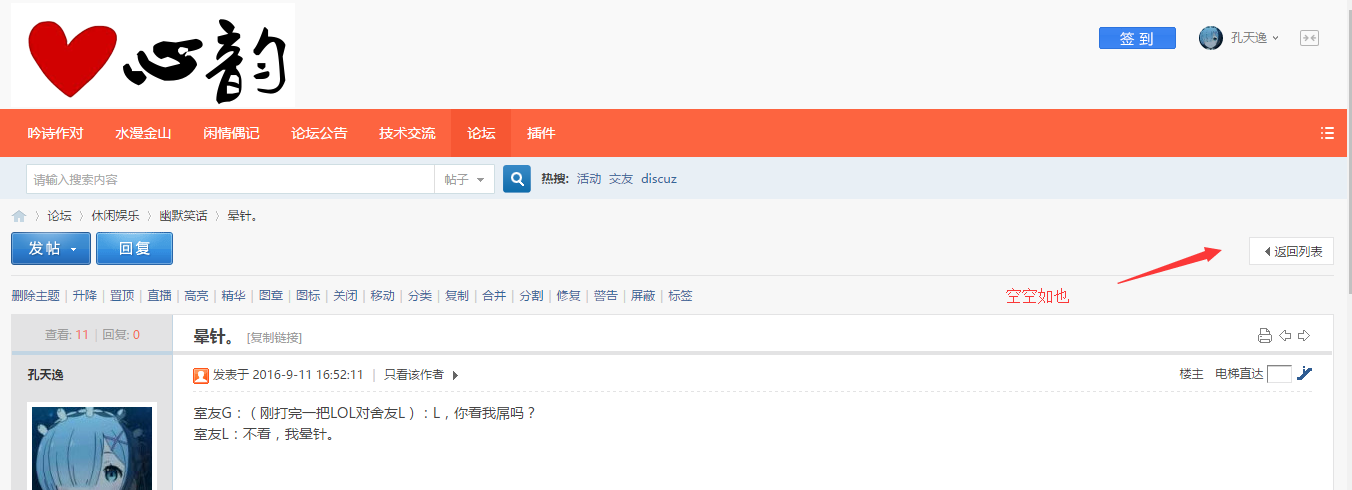
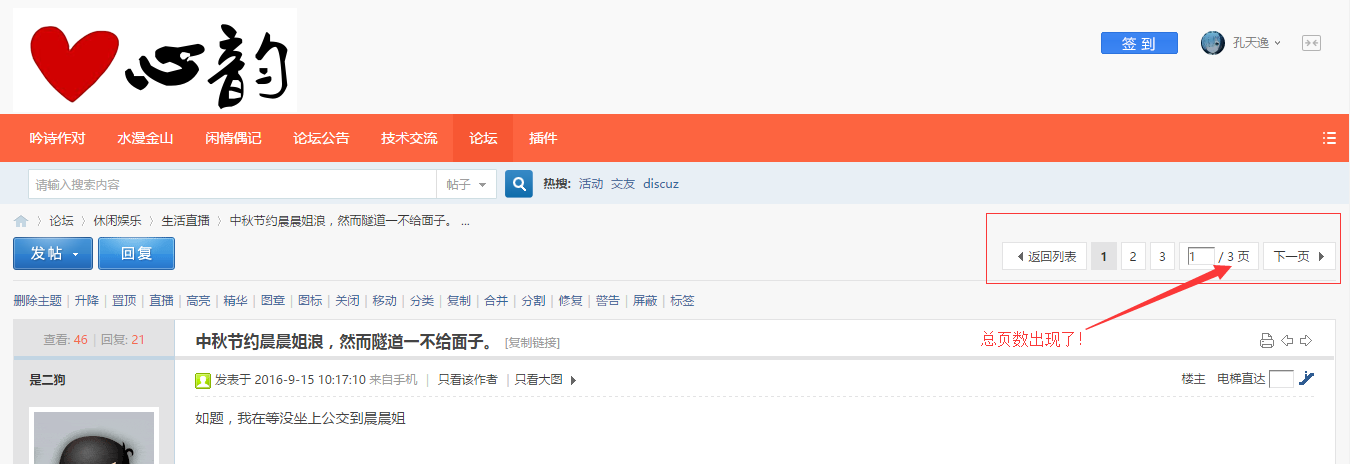
先判断页面内有没有分页的框,通过之前介绍的检查网页元素的办法找到总页数,通过XPath定位,然后通过一个简单的正则把总页数拿出来。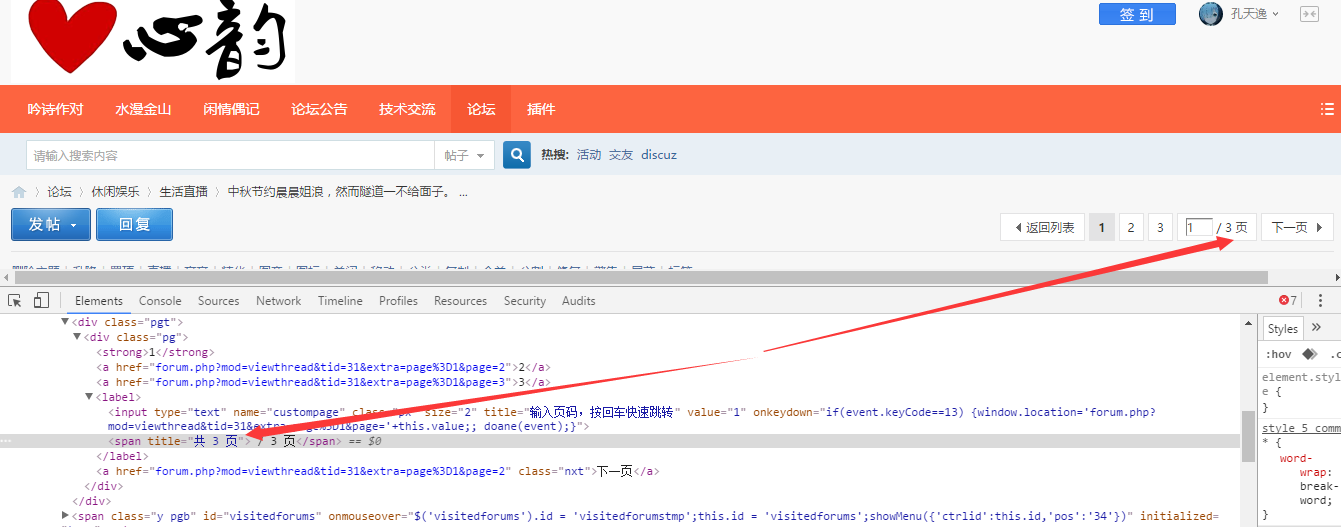
1
2
3
4pages = selector.xpath('//*[@id="pgt"]/div/div/label/span')
if pages: # 如果pages不是空列表,说明该主题帖分页
pages = pages[0].re(r'[0-9]+')[0] # 正则匹配出总页数
print "This post has", pages, "pages"
迭代带page参数的url
分析出了总页数之后,无非就是拼接出子页的url,然后发起Request请求,不过要注意,回调函数不能再是parse了,因为那样的话会在这里无限的生成Request。所以我们需要自己定义一个函数sub_parse,去处理子页的response。1
2
3
4
5
6
7
8
9
10
11# response.url格式: http://www.heartsong.top/forum.php?mod=viewthread&tid=34
# 子utl格式: http://www.heartsong.top/forum.php?mod=viewthread&tid=34&page=1
tmp = response.url.split('=') # 以=分割url
# 循环生成所有子页面的请求
for page_num in xrange(2, int(pages) + 1):
# 构造新的url
sub_url = tmp[0] + '=' + tmp[1] + '=' + tmp[2] + 'page=' + str(page_num)
# 注意此处的回调函数是self.sub_parse,就是说这个请求的response会传到
# self.sub_parse里去处理
yield Request(sub_url,callback=self.sub_parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
sub_parse:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def sub_parse(self, response):
"""
用以爬取主题贴除首页外的其他子页
:param response:
:return:
"""
selector = Selector(response)
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table:
item = HeartsongItem() # 实例化一个item
# 通过XPath匹配信息,注意extract()方法返回的是一个list
item['author'] = each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0]
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
完整代码
settings.py,pipelines.py,item.py相较于第二节都没有改动。heart_song.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134# -*- coding: utf-8 -*-
# import scrapy # 可以用这句代替下面三句,但不推荐
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapy import Request
from heartsong.items import HeartsongItem # 如果报错是pyCharm对目录理解错误的原因,不影响
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
# 起始url,这里设置为从最大tid开始,向0的方向迭代
"http://www.heartsong.top/forum.php?mod=viewthread&tid=34"
]
# 用来保持登录状态,可把chrome上拷贝下来的字符串形式cookie转化成字典形式,粘贴到此处
cookies = {}
# 发送给服务器的http头信息,有的网站需要伪装出浏览器头进行爬取,有的则不需要
headers = {
# 'Connection': 'keep - alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
# 对请求的返回进行处理的配置
meta = {
'dont_redirect': True, # 禁止网页重定向
'handle_httpstatus_list': [301, 302] # 对哪些异常返回进行处理
}
def get_next_url(self, oldUrl):
'''
description: 返回下次迭代的url
:param oldUrl: 上一个爬去过的url
:return: 下次要爬取的url
'''
# 传入的url格式:http://www.heartsong.top/forum.php?mod=viewthread&tid=34
l = oldUrl.split('=') #用等号分割字符串
oldID = int(l[2])
newID = oldID - 1
if newID == 0: # 如果tid迭代到0了,说明网站爬完,爬虫可以结束了
return
newUrl = l[0] + "=" + l[1] + "=" + str(newID) #构造出新的url
return str(newUrl) # 返回新的url
def start_requests(self):
"""
这是一个重载函数,它的作用是发出第一个Request请求
:return:
"""
# 带着headers、cookies去请求self.start_urls[0],返回的response会被送到
# 回调函数parse中
yield Request(self.start_urls[0],
callback=self.parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
def parse(self, response):
"""
用以处理主题贴的首页
:param response:
:return:
"""
selector = Selector(response) # 创建选择器
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
if not table:
# 这个链接内没有一个楼层,说明此主题贴可能被删了,
# 把这类url保存到一个文件里,以便审查原因
print "bad url!"
f = open('badurl.txt', 'a')
f.write(response.url)
f.write('\n')
f.close()
# 发起下一个主题贴的请求
next_url = self.get_next_url(response.url) # response.url就是原请求的url
if next_url != None: # 如果返回了新的url
yield Request(next_url, callback=self.parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
return
for each in table:
item = HeartsongItem() # 实例化一个item
# 通过XPath匹配信息,注意extract()方法返回的是一个list
item['author'] = each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0]
# XPath的string(.)用法,解决标签套标签的情况,具体解释请自行找XPath教程
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
pages = selector.xpath('//*[@id="pgt"]/div/div/label/span')
if pages: # 如果pages不是空列表,说明该主题帖分页
pages = pages[0].re(r'[0-9]+')[0] # 正则匹配出总页数
print "This post has", pages, "pages"
# response.url格式: http://www.heartsong.top/forum.php?mod=viewthread&tid=34
# 子utl格式: http://www.heartsong.top/forum.php?mod=viewthread&tid=34&page=1
tmp = response.url.split('=') # 以=分割url
# 循环生成所有子页面的请求
for page_num in xrange(2, int(pages) + 1):
# 构造新的url
sub_url = tmp[0] + '=' + tmp[1] + '=' + tmp[2] + 'page=' + str(page_num)
# 注意此处的回调函数是self.sub_parse,就是说这个请求的response会传到
# self.sub_parse里去处理
yield Request(sub_url,callback=self.sub_parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
# 发起下一个主题贴的请求
next_url = self.get_next_url(response.url) # response.url就是原请求的url
if next_url != None: # 如果返回了新的url
yield Request(next_url,callback=self.parse, headers=self.headers,
cookies=self.cookies, meta=self.meta)
def sub_parse(self, response):
"""
用以爬取主题贴除首页外的其他子页
:param response:
:return:
"""
selector = Selector(response)
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table:
item = HeartsongItem() # 实例化一个item
# 通过XPath匹配信息,注意extract()方法返回的是一个list
item['author'] = each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0]
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
运行
同教程二。区别在于爬的数据是多个帖子的数据。
小结
至此,一个较为完整的定向爬虫已经写完了,项目地址https://github.com/kongtianyi/heartsong。接下来的教程中,我会介绍如何拓展功能。比如某些帖子内容需要回复可见,我们需要爬虫自动回复。再比如有些网站会检测出你是爬虫然后封你的IP,这时候就需要启用代理。等等……

